Data Pipeline Medicine: Part 1
Henry Bickerstaff, Software Engineer II
Published October 2nd
💡 This post is a introduction to our philosophy of "Data Pipeline Medicine" at Kepler and how we view the different aspects of our data pipelines.
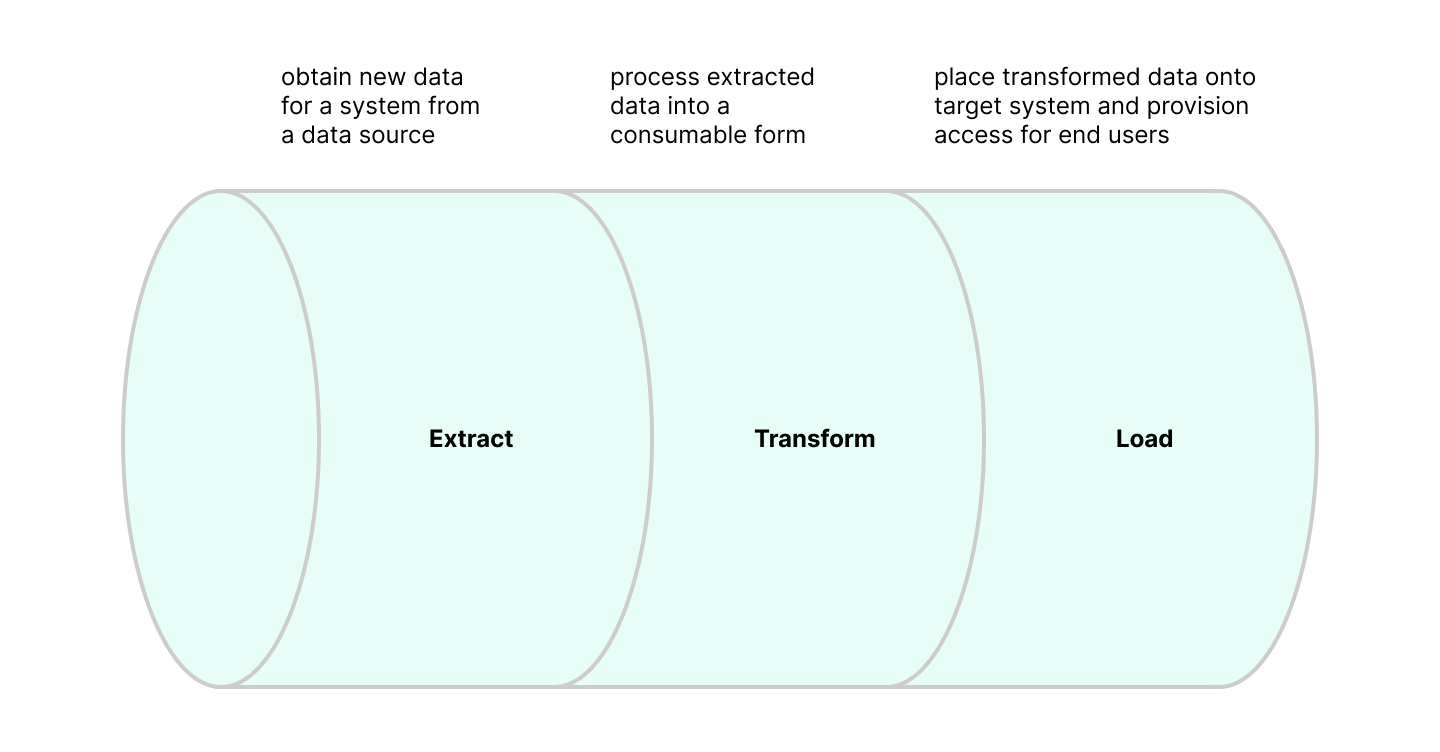
"Data Engineering" can mean many things, depending on where the term is used. On Kepler Group's Technology and Data Services (TDS) team, Data Engineering is a sub-discipline of Software Engineering. Kepler's Data Engineers design, implement, and manage software systems that obtain, transform, and expose acres of raw data-ore into tidy, structured, consumable data sources used by Data Scientists, Analytics teams, and other Engineering teams to create public-facing products. Put colloquially, Kepler's data engineers write code to shepherd data from the pasture to a central distribution facility. This entire process is generally known as "Extract, Transform, Load" (ETL), which describes the component parts of a "Data Pipeline".
ETL and the Data Pipeline
The "Extract" stage obtains "new data" for "a system" from a "data source". Data sources are generally external to the system for which data is obtained, and include Kepler's clients, platforms like Facebook and Google, and other Kepler internal systems. Interfaces through which data sources provide data include APIs, SFTP transfers, direct Amazon S3 transfers, and streaming connections through Amazon Kinesis or Kafka. The extraction step provides raw, unprocessed data for our pipeline's consumption.
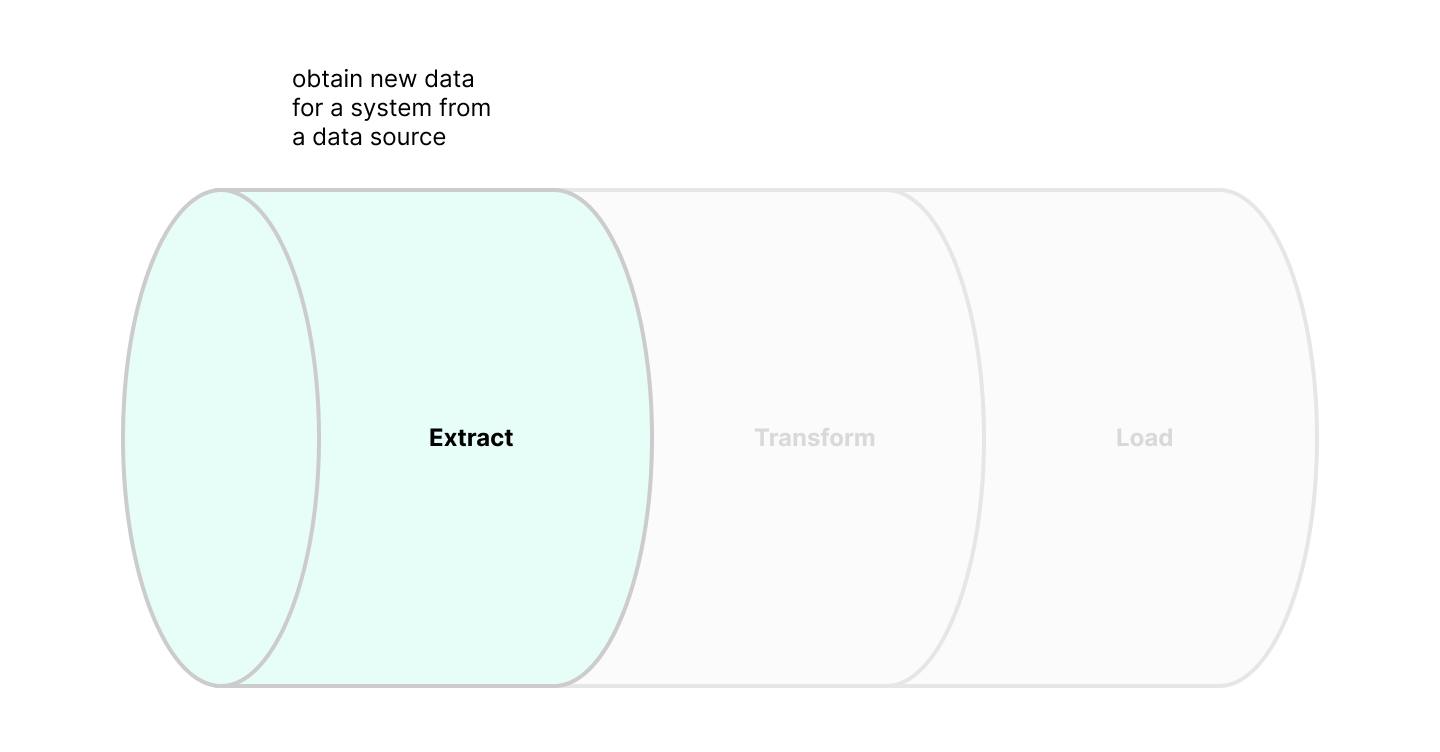
The "Transform" stage processes extracted data into a consumable form. At this stage, Data Engineers will work with end users (Data Scientists, Analytics Teams, other Engineers) to understand how data will be consumed. In practice, users often have specific and varied consumption requirements for each specific piece of data, requiring a variety of transformation techniques that include:
- Altering the format of the data.
- Cleaning the data by removing unwanted anomalies or errors.
- Consolidating multiple sets of raw data into a singular set.
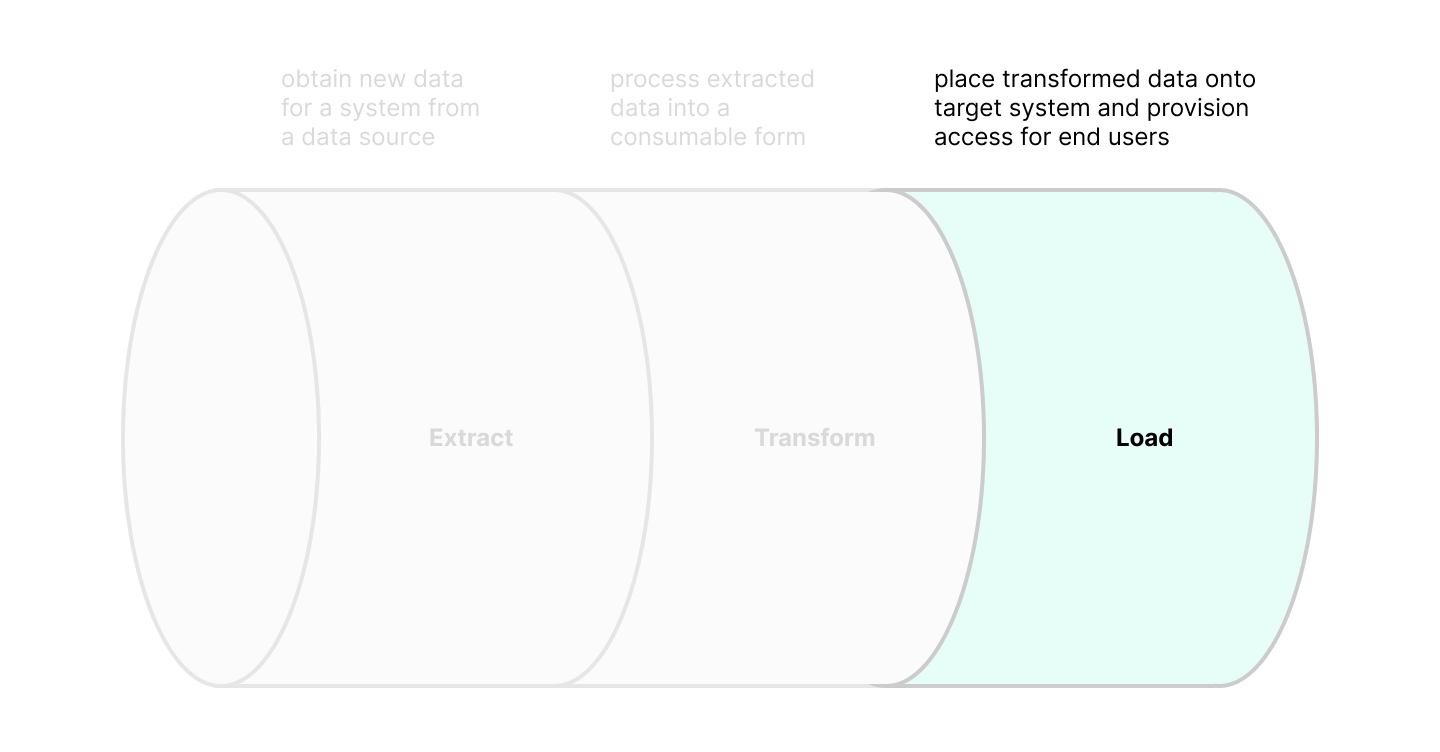
The "Load" stage places transformed data onto its target system and provisions access for end users. This typically involves loading transformed data into a database table that is accessible to data scientists and analysts. Since "placing data" and "provisioning access" are technically separate tasks, the "Load" stage can be divided into two substages: "Storage" and "Access". "Storage" describes the placement of transformed data into a system, while "Access" describes how end users can access the transformed data.
A "Data Pipeline" is the combined form of "Extract", "Transform", and "Load": a set of directions to guide data from one point to another, arriving at its destination in a form that is easily accessed and used by relevant groups of people.
The Medicine
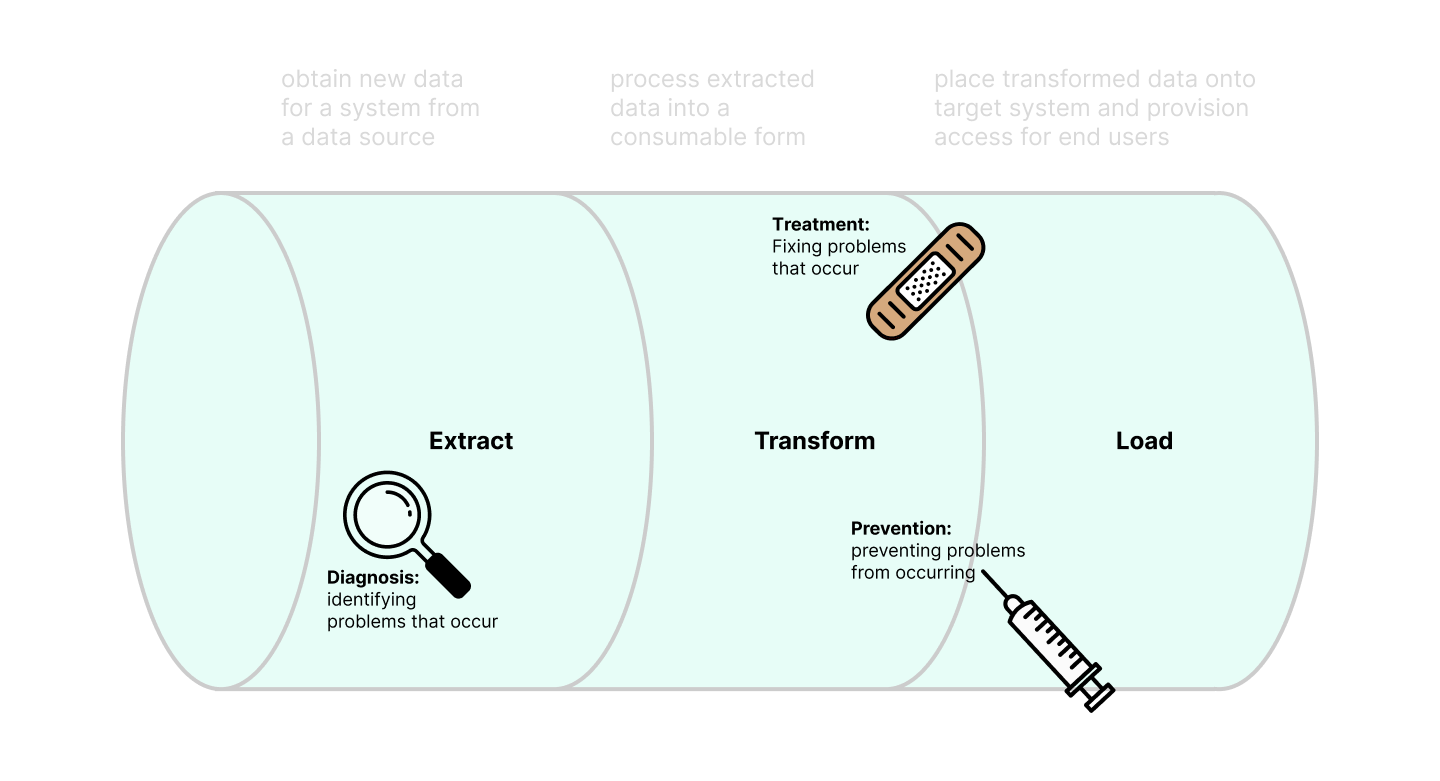
Colloquially "Medicine" can be seen as the science of diagnosis, treating, and preventing disease. We at Kepler Group believe this makes an excellent parrallel to how we look after our data pipelines, and we apply this philosophy under the guise of "Data Pipeline Medicine". Throughout our day-to-day we employ this idea to tackle any challenges that impact our pipelines, and use it as guidance to develop the best future-proof pipelines we can. When an issue occurs we must "diagnose". When an issue is diagnosed, we must "treat" to restore functionality. Finally, once treated, we can take steps to "prevent", making our data pipelines more robust.
Diagnosis is how we identify problems, and is arguably the most important step as without accurate information for what is wrong, how can we expect to treat it? Within our data pipelines this takes the form of utilizing best practices for communication and identification to convey as much information about our systems as possible. This could be as simple as effective logging allowing us to track the progress of our ingestions and receive useful information about errors and their potential causes.
When "treating" a pipeline we typically look to make a code or system change that will fix the issue at hand as well as making the pipeline more robust for the future. The first type of fix is to create a "bandaid" style change designed to nurse the pipeline back to a working state and then further investigation can be launched into a more permanent solution. This is used for our pipelines that are high priority to have high uptime and require a fix to be deployed very quickly after an issue is identified. The second type of "treatment" is a more thorough permanent fix to a pipeline, designed to not only fix the problem at hand, but to prevent similar errors occurring.
As a result of solid robust data pipeline development we can, thankfully, prevent a lot of issues before they occur. Prevention is the most effective form of treatment and is the natural conclusion whenever we successfully fix an issue: to prevent it happening again. Depending on the severity of the solved problem, we may then create documentation to detail the steps taken and how the lessons of one issue can be applied to future issues. This is to say: prevention is incredibly powerful, and doesn't have to just be developing more robust code/systems, it can also apply to the best practices we employ as developers to aid debugging and guide how we write code.
Looking Forward
At Kepler Group our Data Engineering team is responsible for over 50 individual data pipelines, ingesting over 1.5 billion rows of data per day. With such volume comes a necessity to develop robust data pipelines, and we apply the principles of "Data Pipeline Medicine" everyday.
In the next blog post we will explore examples of how we apply these principles within the "Extract" stage of our pipelines.